TANAGRAM: CREATING A DATABASE-BASED CODEBASE
I’ve been working on Tanagram, a programming environment that’s trying to make it easier to browse codebases and build programs by turning code into data. This post is a refinement of previous ideas (see previous posts here), and although it doesn’t look much different from demo 2, a lot of changes have gone in under the hood. Until this past week, my blog has been a standard Phoenix site — most of the URL routes were standard Phoenix paths, rendered by Phoenix controllers and views. Making a change to these routes required a code change and a deploy. But no longer: I’ve implemented my blog routes using building blocks provided by Tanagram, and adding or removing routes now just requires a few clicks:
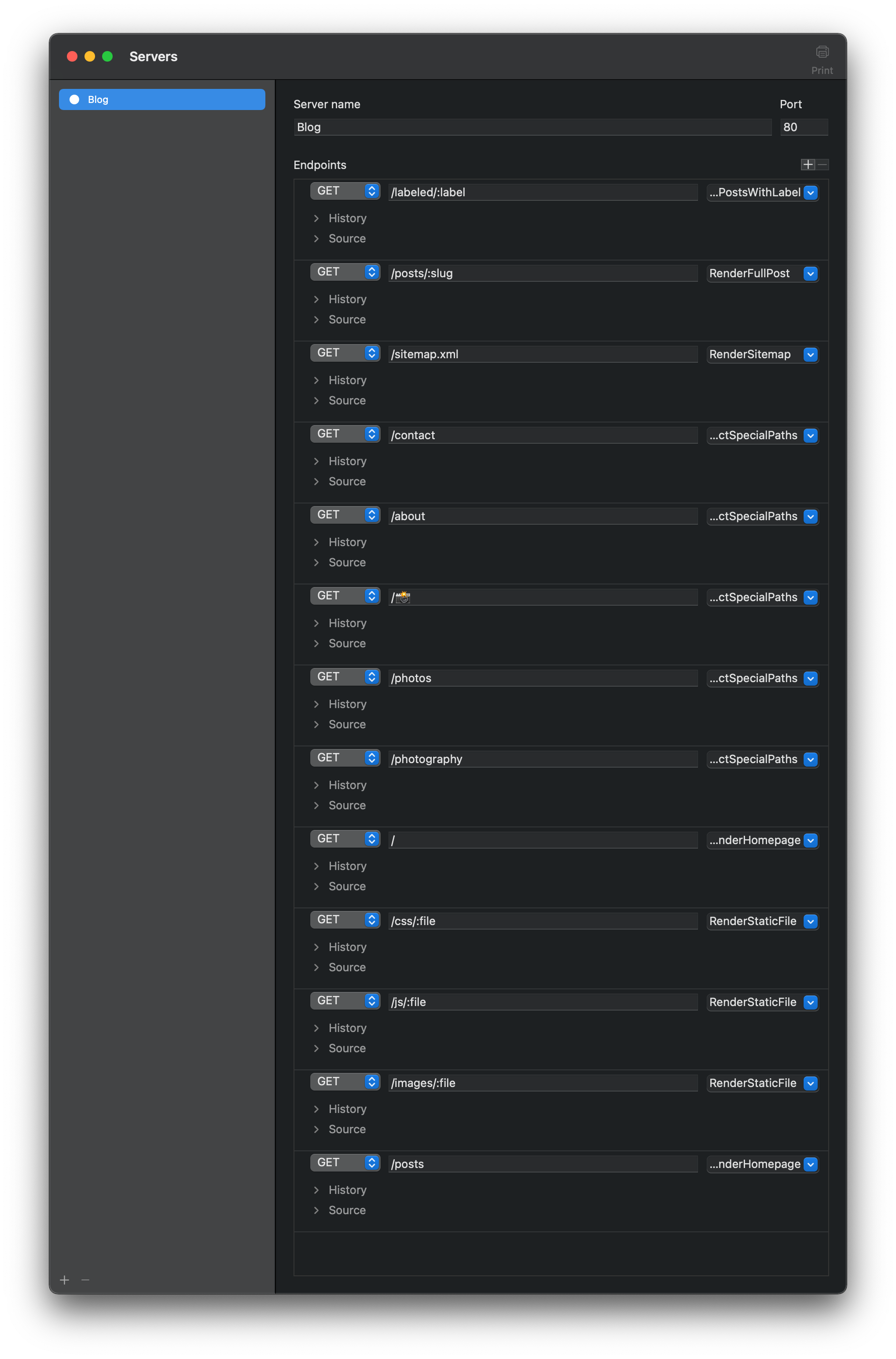
Admittedly, this is just one small example of replacing code with data; it only replaces the routes file with a bunch of Route models.
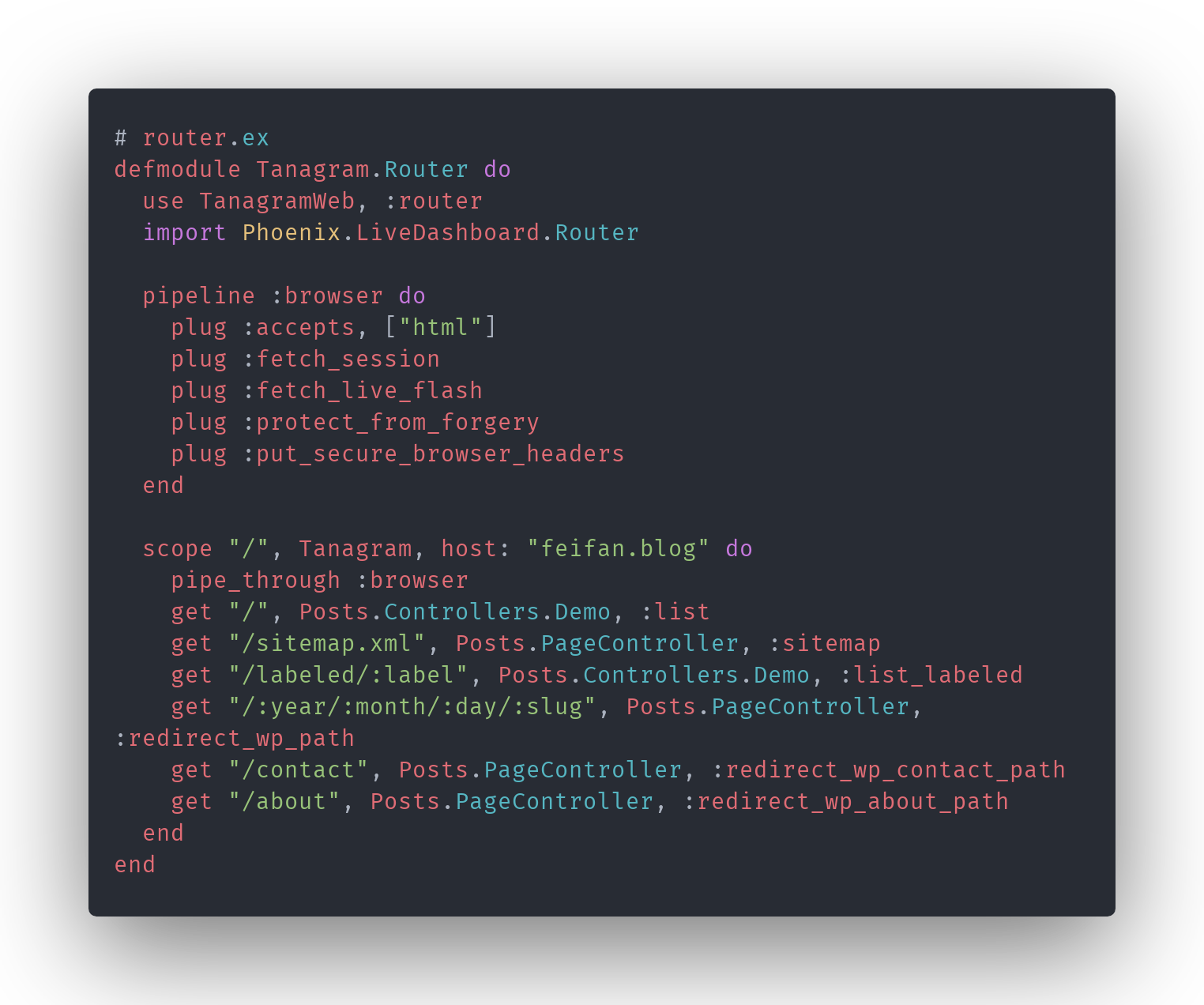
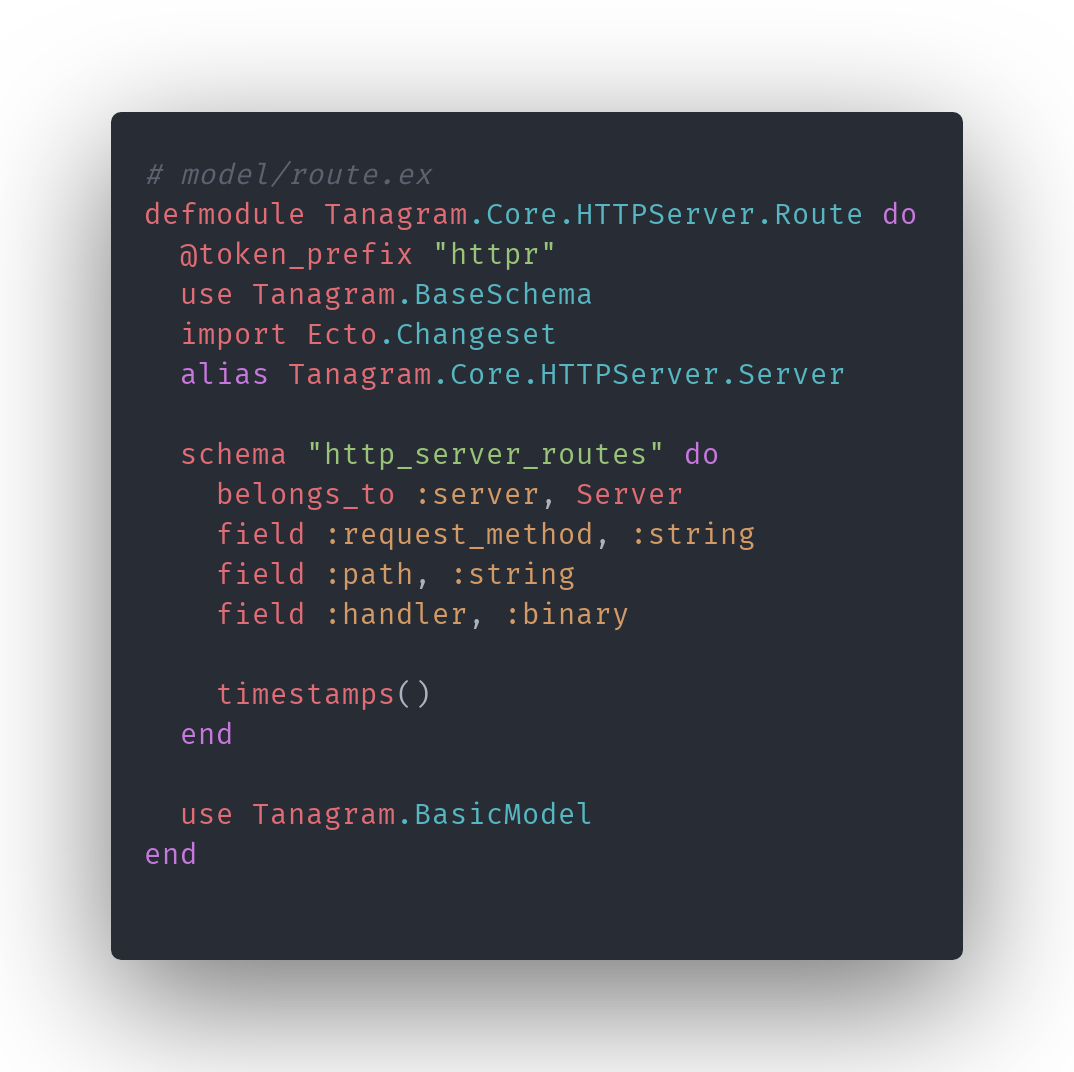
But the underlying idea is bigger: as a computer user, you’re probably very comfortable directly manipulating data in a UI: you might update profile details in a settings screen or even create a new page in a website builder like Wordpress. The amount of effort required to make such a change feels proportional to the complexity of the change. Think you need a new page on your site? Click a button to create one.
That’s working close to the speed of thought.
At some point, though, there’s a discontinuity: you think of a change you want to make to a piece of software, but there’s no exposed way to make that change. You have to edit the code directly, and then everything changes. You need to think about what exactly you want to type, in which file, and whether the eventual output will be what you want, and finally you have to go through a deploy process (which might take a while). That’s a lot of work that isn’t inherently novel or valuable; it’s just the menial effort required to operate an unenlightened computer. You’re now working at a pace rather far-removed from the speed of thought.
Tanagram is an attempt to bridge that gap by providing building blocks[1] for programs — like commands, HTTP servers, and routes — with affordance to make them easily-assembleable in a domain-specific GUI. Tanagram isn’t meant to be a no-code app-builder though: I think plain text can be the best medium for expressing logic — but typically in small, approximately-atomic units. On the other hand, the task of combining those blocks to do interesting things can be done more effectively and expressively in a medium that’s not plain text.
"are we working with objects or just manipulating text ?" https://t.co/swEhh5MvoH pic.twitter.com/ImGHLwIcm0
— Omar Rizwan (@rsnous) February 14, 2021
What’s wrong with plain text code? Its flexibility makes it suitable for everything but great for nothing. Its lack of constraints is its biggest weakness: there’s too many possible ways to express every idea, and as you add more people and lines of code, every one of those ways will eventually find their way into the codebase. Linters help, but they’re more of a crutch than a solution because they can’t understand and enforce constraints that are specific to a small portion of a codebase. Plain text is also fixed into one perspective: it’s generally not possible to transform and browse plain text code from a different perspective than the one in which it was originally written. Every piece of code reflects the proclivities of its author and might be in a format that’s difficult for other people to understand, and there’s nothing you can do about that unless you want to carefully rewrite it.
Instead, the ideal medium for navigating and editing a program should probably be something more substantial — both more rigid in its constructs, as well as more flexible in a way that’s made possible by consistently-applied rules. Language and framework features are a step in the direction of such rules:
- In an idiomatic Ruby codebase, you’re likely to find uses of
mapandselectmethods rather than hand-rolledfor-loop syntax, whereas that’s less likely to be true in an idiomatic Javascript code and unlikely to be true in a C codebase. - In a Rails codebase, you know you can find all the endpoints and corresponding code in the
routes.rbfile, whereas in a custom PHP codebase there may not be such a uniform structure.
These language and framework features become Schelling points: common constructs that everyone knows to use[2] and whose uniformity provide a degree of reliability that can be relied upon. Schelling points in a codebase become harder to identify and codify for custom concepts that are unique to a codebase, and the tools for enforcing them are hard to implement in a plain-text world.
Implicit conventions in a codebase reveal the limits of plain-text. These conventions can be small, contained to a narrow section of a codebase, or they can apply across an entire codebase. Here are some examples of implicit conventions, along with potential solutions enabled by a data-model-based codebase:
Given some production code, how do you find its corresponding test code[3]?
- This typically happens via filename or classname conventions — the test code might be in a sibling
test/folder somewhere in the file hierarchy, with a filename or classname matching the production code and suffixed with “test”. - How about the inverse — given a test, how might you find the corresponding production code? Go-to-definition might work for unit tests, where the corresponding production code is actually in the syntax of the tests, but what if you’re looking at an end-to-end test that invokes an API endpoint?
- What if you’re looking at unit tests for some code and wanted to find the corresponding end-to-end tests?
- What if you’re looking at a test and want to see its run history and whether it’s been flaky recently, or how its CI runtime has been trending over time?
- If you have solutions for your current codebase, how reliably do you think they’d work with, say, ten times the number of engineers working on the codebase containing a hundred times more lines?
The answers are easy if these codebase concepts were stored as database records. Perhaps there’d be a test table, with fields for an id, name, type (e.g. “unit” or “end-to-end”), and implementation[4], along with a table for commands or some other logical unit of production code[5]. There could be a code_test joining table with fields test_id and code_id, and each record in that table would be a bi-directional link between production code and test code. CI results could be stored in the same database, with each run containing a test_id field and how long the test took. All sorts of UIs could be built to display this data and even edit it. For example, there could be an IDE plugin that adds a “create test” button next to each command in production code; clicking it would automatically create the corresponding database records and pre-fill the test name and implementation according to codebase conventions. Furthermore, giving the test a stable ID (one that isn’t based on its name or line number) makes it a real object in the system, mirroring the notion of the test itself in the developer’s mind, and enables a non-brittle integration with runtime results.
As another example, consider enforcing protocols in a plain-text codebase. There are challenges for both the definer and the implementer:
- For the protocol definer, it might be difficult to communicate how protocol methods should be used (akin to the “implementation guides” or “recipes” provided by well-documented APIs) without relying on prose documentation, which is somewhat removed from the code itself.
- It might even be difficult to make implementers aware that a protocol exists, or when it might be relevant. For example, you might have a dashboard that displays information about a variety of data models if those data models implement your protocol; how would you make sure everyone else defining new data models know to do so?
- For protocol implementers, it might be difficult to find reference implementations from elsewhere in the codebase in case it’s not obvious how to implement a particular protocol method.
Solutions to these problems are varied but are more apparent when code can be expressed as data structures. Perhaps there’d be a protocol table with id, name, and methods fields, and an implements_protocol table with protocol_id and code_id fields. You could write code (perhaps as a CI test or notification upon a commit) to ensure that every piece of code that should implement a protocol does so, as well as the specific methods that should implemented. Similarly, developers adding new code could query the codebase database[6] for examples of other implementations.
One final example of the limits of plain-text code that I’ve personally been working with this past week: I needed to write several SQL query templates to automate a reporting process. The queries share a lot of logic; it’s tempting to extract shared clauses into a common place and interpolate them into the query at runtime. But doing it that way makes it more difficult to verify that the queries are syntactically and semantically correct when all the interpolations are expanded: it’s easy to forget parentheses around an interpolated clause and end up with a logical error[7], and shared clauses might assume the existence of table aliases and expect that the rest of the template (and other snippets) declare and also use those same aliases.
I’m not yet sure what a good solution to this would look like, but I do think turning the SQL strings into data structures would help. Perhaps a query could be assembled from a bunch of Clause structs arranged in nested lists (Lisp-style), where the order of operations is unambiguous. Perhaps Clauses of type: from could declare output_aliases, and Clauses of type: where could declare input_aliases, and a Query object built from these Clauses could be statically checked for compatibility.
One important clarification: I’m not describing a system where queries are built from data structures at runtime with code like query.append(clause). I’m describing a system where clauses are building blocks available in the code editor, and you assemble them into a query the same way you might build a UI in Visual Basic or Xcode’s storyboards[8]. That query can then be statically checked for correctness and committed into the codebase.
Across these examples, the data-structure solutions reify implicit ideas that already exist in the plain-text version. By making these ideas explicit, they become more visible and more likely to become Schelling points, leading to a codebase where there’s only a finite set of ways (and ideally only one way) to express an idea. You can enforce conformity through database constraints and custom data-integrity-checking code. While this may sound constraining compared to expressive, “almost like English” code and custom DSLs, it enables a more valuable type of freedom: the freedom to build domain-specific UIs for programming different parts of the system, rather than having to express everything through textual approximations. You could have a calendar-based interface for managing cron jobs, a table-based interface for designing data models, a canvas with boxes and arrows for specifying pubs pipelines or a state machine, a storyboard-based interface for laying out UIs and data-binding, or anything else that makes sense for you — all editing the same codebase behind the scenes. These visual interfaces can be customized to specific tasks and even specific programmers or teams. They offer the expressiveness of information hierarchies, directly-manipulatable controls, and opportunities to surface relationships — degrees of freedom that don’t exist with plain-text. In fact, plain-text becomes one possible interface to such a codebase; the system could generate an entire syntactically-valid plain-text-codebase from a data-structure codebase and keep it up-to-date as changes are made to the underlying data structures. Maybe the plain-text output could even be editable (albeit with limited degrees of freedom such that changes can be translated back into data structures). This could be useful for maintaining interoperability with an existing plain-text codebase.
So what’s next for Tanagram? I don’t think the idea of a database-codebase is particularly complicated, but building a product around it is. I don’t expect Tanagram to become widely-adopted if it only provides a fixed set of built-in data structures (like the HTTP servers and routes from demo 2). I believe that, for it to be valuable, it needs to provide a way for every developer and team to define their own data schema to model concepts that are unique to each codebase and the rules for how pieces do and don’t fit together. Additionally, there has to be virtually zero cognitive overhead to doing so: it shouldn’t be a chore to define a new data structure and build with it, because the alternative — just start typing — is readily within reach. I’m convinced, though, that building a database-codebase environment is critical for making programming easier and less frictionful, for enabling people to work at the speed of thought, and for making computers truly personal[9].
Thanks to Eric Gade, Tanishq Kancharla, and Joe Antonakakis for reviewing drafts and providing feedback.
And, eventually, building blocks for building your own building blocks. ↩︎
And if you don’t know about them, someone will probably suggest you use them in code review. ↩︎
Finding “corresponding” code is a whole problem category that is very codebase-specific and, beyond go-to-definition, is not well-served by plain-text tools. Another example that I like to use: for pubsub/event-based code, how do you find all the code that consumes an event from a given publisher, or all the code that publishes an event from a given consumer? ↩︎
The contents of the
implementationfield don’t matter for this example. Possible options include textual source code, compiled bytecode, or a (pointer to a) standalone executable. ↩︎The fields of this table are left as an exercise to the reader. You’ll probably want to include a stable
idfield though. ↩︎In SQL, perhaps something like
SELECT code.pointer FROM code c JOIN implements_protocol ip ON ip.code_id = c.id JOIN protocol p on p.id = ip.protocol_id WHERE p.name = '…'↩︎Suppose you have a
WHEREclause in the template likeWHERE a AND b AND {{x}}, wherexis an interpolated clause. Ifxgets filled in with a clause likey OR z, the lack of parentheses around the interpolation would mean this behaves like(a AND b AND y) OR z, which is probably not what the author ofxintended. ↩︎The actual UI for doing so is left as an exercise for the reader. ↩︎