TANAGRAM DEMO #2
I’ve been working on a new way of writing and working with software. This is the second demo (demo #1 here), and although this, too, looks like a toy, I think it’s a good encapsulation of what I’m trying to solve with Tanagram. In short, Tanagram is a programming environment that’s trying to make it easier to browse codebases and write glue code (i.e. boilerplate code; code where remembering the exact syntax is harder than the logic itself) by putting codebase concepts into a database and replacing some typing with a GUI.
It doesn’t look very impressive. After all, it’s just a bunch of stock AppKit controls[1] in a haphazard UI, and there are many obvious additional features I could build. But this isn’t meant to be a feature demo; instead it’s a small illustration of how I’d like to be able to build software. To put this illustration in perspective, I’d like to first talk about the problems I have with plain-text codebases.
Imagine building a RESTful API. The API has concepts (“resources” in REST parlance, e.g. Account or Product), properties for each resource (e.g. name or price), and a set of capabilities for each resource (e.g. create, update, or delete).
A codebase is first-and-foremost an API for other developers (including future-you). Like a RESTful API, a codebase also has concepts (e.g. models or cron jobs), properties for each concept (e.g. data-locality annotations on models or the run schedule for cron jobs), and things you can do with each concept (e.g. querying for model instances from the database or viewing the run history of cron jobs).
In an API, these structures are well-defined. There’s code making sure inputs are well-formed. There’s code that massages inputs into consistent shapes before writing values into the database. There’s code making sure outputs are well-formed.
In contrast, codebases are just arbitrary plain text, semi-successfully held together by syntax validity and linting rules. There’s nothing stopping someone from re-writing chunks of the codebase as part of a refactor[2], or even just splitting a line of code into multiple lines and reducing grepability. There’s nothing stopping someone from reinventing the wheel and implementing a different syntax to do the same thing as some other part of the codebase[3]. And it’s difficult (or at best tedious) to build interfaces to view and query codebase concepts, or to integrate code with runtime data[4].
Instead, what if codebase concepts worked the same way as API concepts — i.e. as uniform records that live in a database, that can be inputted through a variety of interfaces, and outputted or queried in a variety of formats as well? What if you could build programs through a GUI — not one that forces someone’s arbitrary no-code feature set on you, but one that has the exact concepts and capabilities that are relevant to your corner of the codebase?
That brings us back to the demo. The server I built in that demo could equivalently be written like this in code:
require 'sinatra'
get '/greet/:name' do
"Hello #{params['name']}"
end
get '/greet' do
"Hello #{params['name']}"
end
If you asked me what this code does, I might say that this code creates an HTTP server with a couple of endpoints, and each endpoint runs its respective handler. But the physical act of typing code in a particular way is one step removed from the conceptual act of creating a server. It’s not a big deal in this particular case; the code is pretty easy and I only needed to look up one thing to write that example code by hand. This isn’t always the case. As a codebase gets larger and deviates further from a single canonical way of doing things, figuring out the exact syntax to write becomes more difficult than the implementation logic itself. If you spend time searching the codebase for existing code that does something similar to what you’re trying to do, and then copying it and changing a little bit of it for your particular situation, you know what I mean. By comparison, it feels a lot more direct and flow-state-y to think that I need to create a server (or add an endpoint to an existing server) and then being able to just click a button to make it so.
Admittedly, appending a few consecutive lines to a source file doesn’t seem too difficult. In real codebases, adding a new “thing” can actually involve changes across dozens of files over multiple steps (which are hopefully documented somewhere). To paraphrase a real example I worked on: in this codebase, users have a balance and various types of events can affect a balance. To add a new event type, it required changing code in over 50 places[5], all to do what amounted to a single line item on a project schedule: “Add new event type”. Event types were a distinct concept in the codebase, but the relevant code encompassed a large cross-section of the codebase. None of the code changes required much thought; the only hard part was figuring out the entire extent of places to change.
Code generation is one type of tool that can help reduce the amount of glue code you need to find and type out — it would theoretically have been possible to write a tool that automated most of the work of adding a new event type given the event type name[6]. Similarly, Rails includes built-in generators to create models, controllers, corresponding test files, and more, in appropriately-named files placed in their proper directories. But most code generation tools (rails generate included) are command-line tools, with the attendant discoverability and usability challenges[7]. The Tanagram approach makes it possible to create code generation UIs that look more like filling out Mad Libs, with labels and explanations for each input field, the ability to surface the necessity (or lack thereof) of certain fields, and live previews of the code that would be generated.
Code generation can help write code, but it doesn’t do anything for finding existing code. Finding the code that corresponds to runtime results[8] can be difficult, but this difficulty is self-inflicted — grepping with regexes across imprecisely-formatted text files is not a particularly robust way of searching. We generally don’t store data records in plain-text flat files; we store them in databases with well-defined schemas and indexes, and find specific subsets by writing expressive queries. These records become data structures that can be further queried and transformed with application code to get the exact data you want.
The same should be possible for code. Codebase concepts should exist as records in a database, with defined schemas and expressive queries. This version of Tanagram implements this idea for the servers and routes — they are literally records in a database.
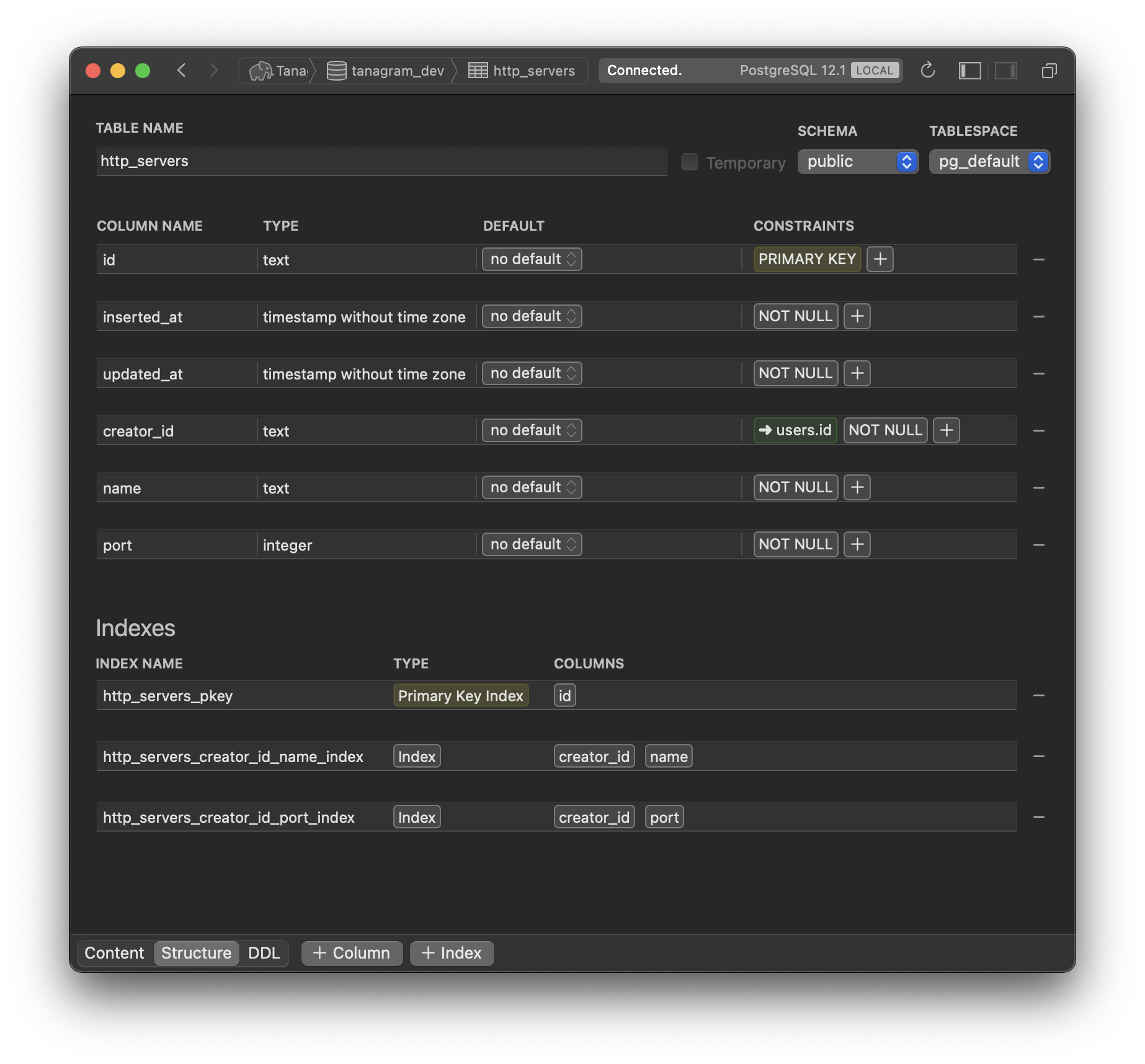
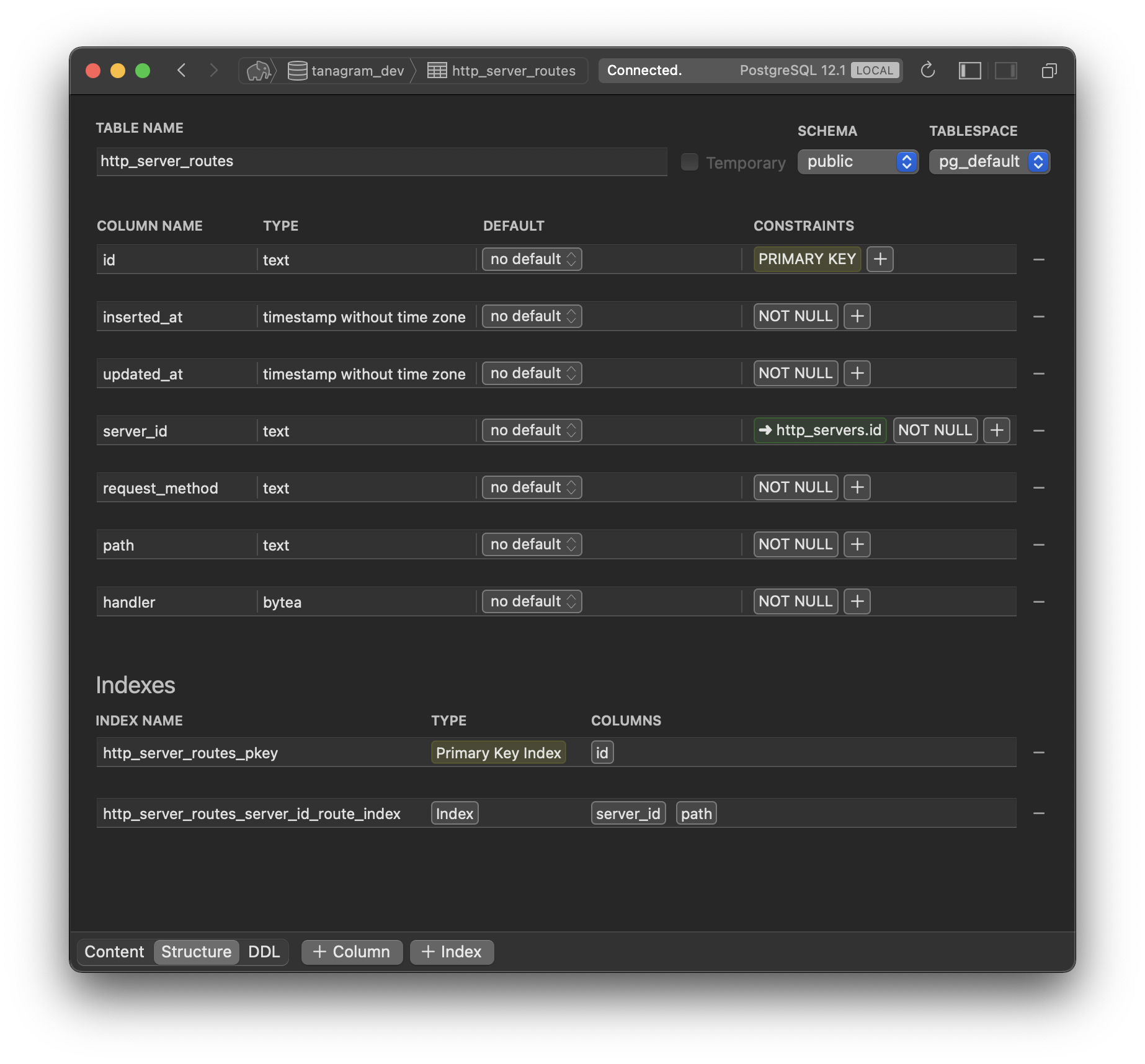
Servers and routes can be retrieved through an API, which can be used to drive a UI for managing them. They can also be queried through SQL, making it easy to browse the “codebase”. They can be loaded into a REPL to dynamically find what you’re looking for — for example, given a URL, you could find its implementation with a one-liner like Routes.load_all.find { |route| route.match?('/example/url') }.handler. That’s much harder to do if your routes only exist as chunks of text across multiple files.
Of course, it’s also easy to turn database records into source code that you might’ve otherwise written:
# Assuming you have an array of Route objects loaded from a database
preamble = [
"require 'sinatra'"
]
body = routes.map do |route|
(
<<~EOM
#{route.http_method.downcase} '#{route.path}' do
#{route.handler}.call(params)
end
EOM
).strip
end
lines = preamble + body
print lines.join("\n\n")
The output of this function would always be internally consistent. Refactors would be as easy as changing the implementation of relevant functions[9] and re-running them to re-generate the entire codebase.
But why bother outputting code at all? It might be useful for interop with an existing codebase. For new projects though, you can do something with those database records directly. They’re real data structures and objects that can be used to actually do things. In the demo video, Tanagram loads the server record and its routes from the database and wraps them in an HTTP server. Every time an HTTP request comes in, Tanagram searches through the server.routes list to find a matching handler (which is either an anonymous function or a command), executes it, and returns the result. It’s just data structures and a runtime, no syntactical glue needed. Notably, the handlers themselves still contain plain-text code[10]. Tanagram isn’t meant to be an entirely no-code solution — the existence of the GUI is very much meant to be a way for you to spend more time writing the fun code, and less on the rest.
The Tanagram interface isn’t meant to be a static, pre-packaged version of my design sensibilities. Instead, it should be a starting point for you to create UIs specific to things you need to do. I haven’t yet decided how this will be implemented, but it might be something like: Tanagram provides a library of robust UI components — not only buttons and text fields, but also things like multi-dimensional tables, charts and 3D visualizations, and improved scroll views — and a couple of interoperable ways of combining those components into cohesive UIs. One of those ways might be an Interface Builder-like visual builder. Another might be a declarative syntax similar to SwiftUI. And for some simple cases, the UI could automatically be generated from lower-level data models without you needing to explicitly build it.
If you’re a webmaster overseeing multiple sites and pages on those sites, the interface in this demo might actually be useful for you. If you work with a lot of cron jobs, you could create a relevant UI by writing a query whose rows and columns define a table, in which edits you make get dispatched to commands you implement to propagate changes back to the database and runtime. If you just need to collect some data from people, you could define a data model and have Tanagram automatically generate a form UI for its fields. You could start from a blank canvas and draw an interactive system diagram that always stays up-to-date with the code, and then perhaps load a request trace and have it light up the relevant parts of that diagram. You could share these interfaces with your team, or keep them private for yourself.
Plain text seems quite primitive by comparison.
Thanks to Tanishq Kancharla for reading early drafts and suggesting edits.
Why AppKit? Professionally, there seems to be near-universal disdain for Electron apps among programmers (or at least within a thousand-true-fans–sized subset), so much so that I think Tanagram being a truly native app could actually be its own selling point. Personally, I really dislike writing Javascript and working with all the associated tooling, and I find myself just as productive (if not more) building UIs in Swift with AppKit controls. ↩︎
Refactors are often just trading someone else’s comprehensibility for your own. ↩︎
If you work on a web app whose codebase has been around for at least a few years, how many different syntactic patterns for URL matching are there? Maybe one for the marketing site, one for the main API, and one or more for various admin pages. If you work on the main API and need to fix a bug in an admin page but you’re not familiar with that part of the codebase, how do you find the code for that admin page? ↩︎
For example, loading a sample of what the data for a particular model field looks like “next to” the code for that model, or seeing the run history of a cron job “next to” the code for that cron job. ↩︎
If you’re curious, the changes included identifying or creating a model that corresponded to the event itself, adding the
typename to the canonical enum, adding thetypename to related enums (e.g. a public enum if the type was meant to be user-facing or an undocumented enum if not), defining the event-to-type mapping, creating a factory class, adding the type to a dozen places in aggregation and reporting code, updating all the corresponding test code, generating API specs and protobufs — and several more changes to support internal reporting and metrics. ↩︎In practice, such a tool would only work until the next time someone decided to rearrange the codebase. ↩︎
For example, it’s often difficult to figure out what CLI commands can do without seeing usage examples and copying them, some operations are ungainly to represent in plain text, and CLIs are often not resistant to typos. Filling out a GUI form requires much less thinking and can be less error-prone (e.g. through input validation and more expressive ways of inputting complex values). ↩︎
Runtime results could mean something like a component on a page that is perhaps rendering the wrong data, or an invalid database record that causes application code to crash trying to load it. The corresponding code might be the implementation of the component itself or the API code that provides its data, or the various constructors and mutators that might’ve inserted or updated that database record. ↩︎
How would you find the relevant functions? The functions themselves could be represented as data records with attributes that describe what sort of code they output. You could then query the functions with something along the lines of:
SELECT * FROM codegen_functions WHERE output_type = 'http_server_route'. ↩︎Currently, the handlers are entirely implemented as plain-text code that just happens to follow a known interface. But that doesn’t necessarily have to be the case — future versions of Tanagram will support other types of database-defined code that the runtime will know how to invoke, just like functions and methods. ↩︎