BUILDING A NEW BLOG
I’ve moved my blog off of Wordpress — in part because of limitations with Wordpress.com’s hosted offering[1] — and onto a custom-built site[2].
I mainly did this to serve as a proof-of-concept for implementing a blog on the first primitives that come from Tanagram, a project I’ve been tinkering with over the past few months[3]. Tanagram is, in part, a bunch of simple, transparent data types and functions that operate on those data types and return updated data. This, I hope, will make it much easier to build boring software — and that’s a good thing! Most software ideas are essentially variations on cookie-cutter themes, and Tanagram should provide the setup and primitives to make the process of building software like that as quick and easy as, say, writing an essay.
The Tanagram data model I’ve built so far for my blog looks like a “graph of generic items”. Currently, the nodes on this graph are PostItems and FileItems, representing posts themselves and opaque files (mainly images for now). Edges are implemented as directional Links, from one item to another.
Both items and links can have labels applied to them; labels can be used in queries (e.g. all the published posts on my blog have the blog-public label and I can create new posts without that label to keep them in draft status). In the future, labels will be able to trigger actions when they’re added or removed (e.g. when the blog-public label is added to an item, tweet a link to it, email subscribers, etc).
Labels are also used to implement semantically-meaningful roles for links — from node types can define a set of linked roles, and other items can be linked to fill those roles. For example, a PostItem can be linked to many images, but I use a hero_image role to identify a specific link as the one pointing to the image that should be shown at the top of some posts and shown in previews when shared on various websites.
The website that you’re reading this on now is essentially a view over (some of) these data records in a database; the homepage is just a “list of posts”. But you can also view this data via GraphQL:
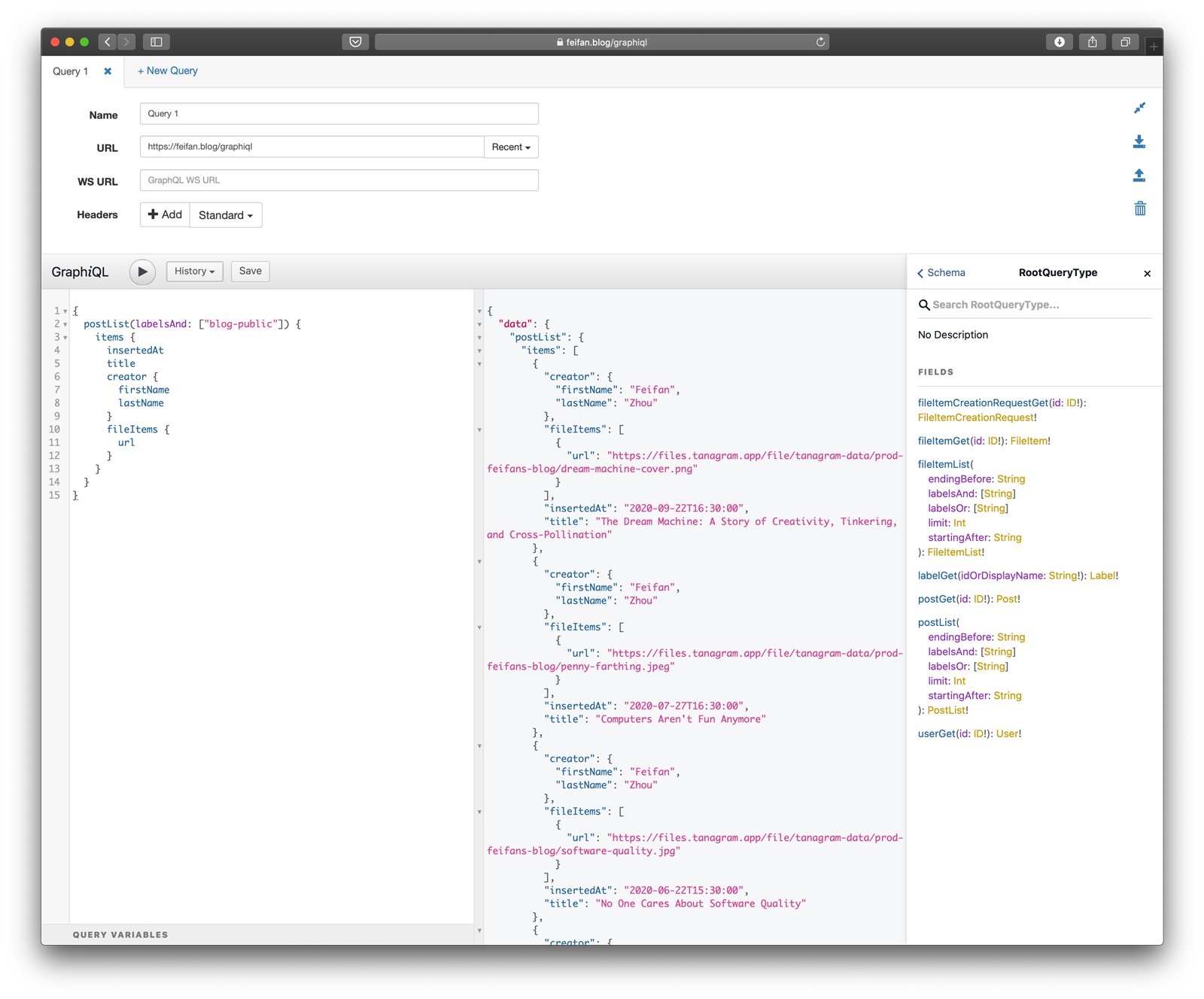
In particular, the postList query executes the same query as the blog homepage. This returns an intermediate object that is conceptually similar to the Connections spec[4]. As it’s currently implemented, it allows you to query by post labels using either the labelsAnd argument to find posts that contain the intersection of the labels you specify, and the labelsOr argument to find posts that contain the union of the labels you specify. This query uses Dataloader to efficiently join in nested objects like the creator and fileItems.
Similarly, the fileItemList query allows you to list all files. This query isn’t as fully-developed, but it could be used to e.g. query for files that are hero_images on posts vs those for a different purpose.
What’s the point of doing all this? To quote Joe Armstrong[5], “we want the same way to program large and small scale systems”. Similarly, I want to have a single set of primitives that let me program a range of software in the same way. For example, I could use the same primitives I’ve currently implemented for my blog to model an Evernote-like personal notebook, and then automatically publish a “note” as a blog post just by adding the blog-public label. This is much easier than the programming paradigm we have today, where my notes would live in a separate app with its own data model and which would need a custom-built integration to publish to any blog (and only if the note app exposed an integration point or deigned to implement the feature for you). These same primitives could also model an email inbox, with posts linked to other posts to represent email threads and actions triggered when apply labels to emails (e.g. applying the “Snooze” label could schedule a command to resurface a message in my inbox tomorrow morning). In both examples, the “apply label” action is a common integration point that can be used to trigger other behavior — it’s a core primitive that provides a consistent way to program all sorts of systems and use cases.
Over time I’m planning on exploring and building more reusable data models and primitives to provide a consistent way to build boring software. Much more to come!
Including footnote support ↩︎
Stack specs for the curious: Elixir + Postgres + Vanilla JS + Gigalixir + Backblaze B2 + Cloudflare. ↩︎
I’ve previously written about Tanagram. ↩︎
There’s no good reason why my
PostListobject doesn’t adhere to the Connections spec other than the fact that I forgot it existed until just now 😅 Rather than introducing another format, I’ll probably update my implementation to follow the Connections spec. ↩︎Joe Armstrong (1950–2019) was a much-beloved computer scientist in the field of distributed computing systems. He’s perhaps best known for being one of the creators of the Erlang programming language (which Elixir is built upon). ↩︎