TANAGRAM ROADMAP: DECEMBER 2023
This is my 23rd monthly public roadmap update for Tanagram development (I’ll stop counting after this one; see previous updates here). Tanagram remains a nights-and-weekends project. My progress pace over the past month has averaged about 1.0 workdays per week; some personal errands and day-job projects have kept me busier than usual.
Would you like to receive these updates over email? I’m also publishing these to my Buttondown newsletter. Click here to subscribe.
Results: November 2023
After my talk earlier this month (slides available here), I got a bunch of enthusiastic follow-up from people in the audience. Many of them worked/had worked at big tech companies, and described problems they were facing that they could imagine Tanagram solving:
- One person had spent several weeks in one case fixing a major app that couldn’t be compiled because of broken internal dependencies. Within the company, different teams developed independent packages, all combined into the main app. However, package developers had no idea how their code was used, so they would make breaking changes, and those breakages would only be discovered once they tried compiling the main app. This person was excited about Tanagram being able to give package developers more visibility into how their code was being used.
- Another person worked on a code-infrastructure team for a popular consumer-facing app, and described several problems they’re facing that they thought Tanagram could help solve:
- They wanted to find code that had broader visibility than was actually needed (e.g.
publicmethods that could instead be madeinternalorpackagevisibility), which would speed up compile times. - Similarly, they wanted to identify infrequently-referenced code, so they could potentially replace that code with other existing code, thereby reducing compile times and output size.
- They were running out of stack memory on deep call stacks, so they wanted to identify code paths with very deep call stacks to see if they could be rewritten or optimized. They currently have no way to do this except guessing, putting breakpoints, and counting stack frames.
- They wanted to find code that had broader visibility than was actually needed (e.g.
I also had a conversation with another potential user for whom it seemed like Tanagram wouldn’t offer much value:
- They’d previously owned a cross-cutting area of a very large codebase — so large that, in their role, it didn’t make sense to actually understand how the code worked. To do their job, they would instead develop relationships with the right people on other teams, and describe what they were seeing for the other teams to solve.
- In their current role (working as a mostly-solo developer on a smaller project), they rarely run into something beyond the ability of Xcode’s built-in text search and Jump To Definition. In particular, they’re rarely bottlenecked by searching for some known concept; they’re either reading through existing code to form hypotheses, or going directly to some code they know exists.
- They did describe one potentially-valuable interaction: being able to get an “overview” of some subset of the codebase, looking for specific patterns like early returns from methods, or places with
do/catchblocks that might be swallowing errors.
- They did describe one potentially-valuable interaction: being able to get an “overview” of some subset of the codebase, looking for specific patterns like early returns from methods, or places with
This feedback, taken together along with feedback from previous months and my personal experience, reinforces my hypothesis that Tanagram will be most useful for developers working on moderately-large codebases. Roughly quantified, I’d guess that’s maybe 100,000–10,000,000 lines of code. In this range, developers will often need to search for constructs they know exist (or guess at what they think might potentially exist) and will need help mapping longer paths through the codebase, but still small enough that they could conceivably understand a large part of it and have the ability to make cross-cutting changes.
I spent my development time this month on a few things:
- I sped up Tanagram’s build time by forking
XCLogParserto remove a slow-compiling dependencyand breaking up slow-compiling functions into smaller functions. This improves my development cycle, as well as the clean builds I currently have to do to browse Tanagram’s own codebase. - I got some help investigating the very slow initial
prepareCallHierarchyrequest I’ve been seeing. It turns out that this is somewhat of a side effect of how I’m using SourceKit-LSP. It’s been dramatically improved in recent commits to the Swift toolchain, which I could incorporate now if I wanted to build a custom build of SourceKit-LSP (I haven’t done so yet). - I used my actor refactor from last month to improve the first-open experience — now Tanagram will automatically load all symbols, make the first
prepareCallHierarchyrequest (which serves to “warm up” the server), and show its status while doing so without any user interaction (previously, the user had to click twice to make all that happen). - Finally, I sketched some designs for Tanagram’s search feature (attached below). Users will be able to search for specific symbols, paths through the reference graph, or locations in codebase matching a broad range of criteria. I’ve also started figuring out the implementation of this UI, which has involved a lot of lower-level AppKit code so far.
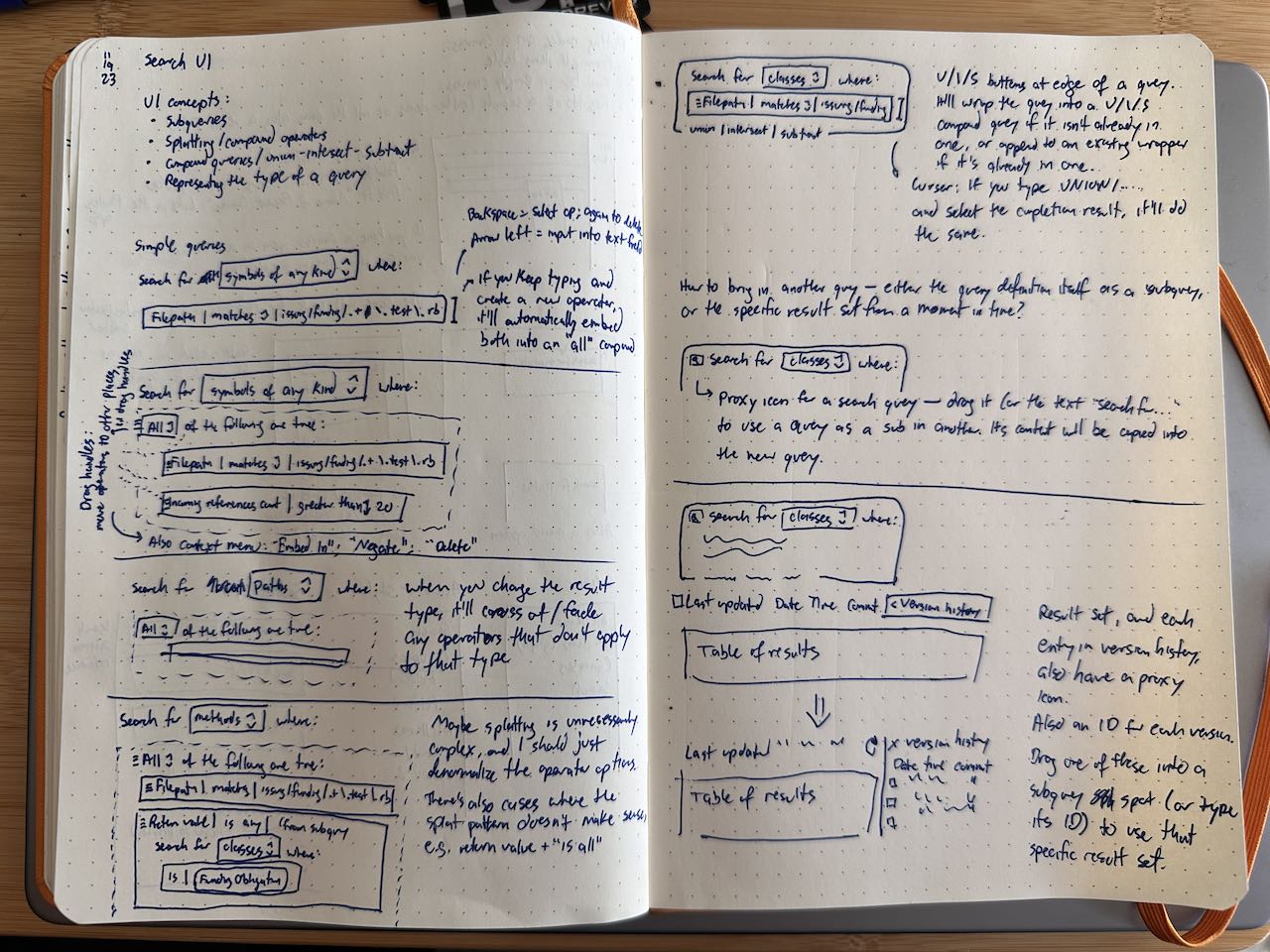
Roadmap: December 2023
December will be a short work month for me — between the holidays and vacation plans, I’ll have a bit less than two weeks’ worth of work time this month. I plan to spend it building my search UI, described above.