TANAGRAM FEATURES GUIDE
Updated for version 202309-01
Welcome View
 When you first launch Tanagram, you’ll see the Welcome view. Here, you’ll see a list of recently-opened projects in the sidebar, and a button to open any project you’d like.
When you first launch Tanagram, you’ll see the Welcome view. Here, you’ll see a list of recently-opened projects in the sidebar, and a button to open any project you’d like.
Tanagram can open any directory containing source code files on your computer. Tanagram only performs static analysis on your code; i.e. it doesn’t attempt to build or run your code. As a result, you can open directories that are a subset of a bigger codebase, or works-in-progress that don’t yet build. Tanagram can only analyze one programming language at a time though, and it’ll automatically attempt to determine the language based on the filenames in the given directory. Tanagram currently has the best support for Typescript/Javascript (both of those can be mixed in the same project).
When you open a directory, Tanagram will add a ProjectConfig.tanagramvizproj file. This file is a macOS package. It currently contains a JSON file containing project-specific settings (more on that below), and, if you’ve defined any custom item types (more on that below), a binary file for those definitions.
Note that Tanagram currently does not persist information about your codebase itself to disk — all the data displayed in the main view is loaded and stored in-memory for now.
Main View
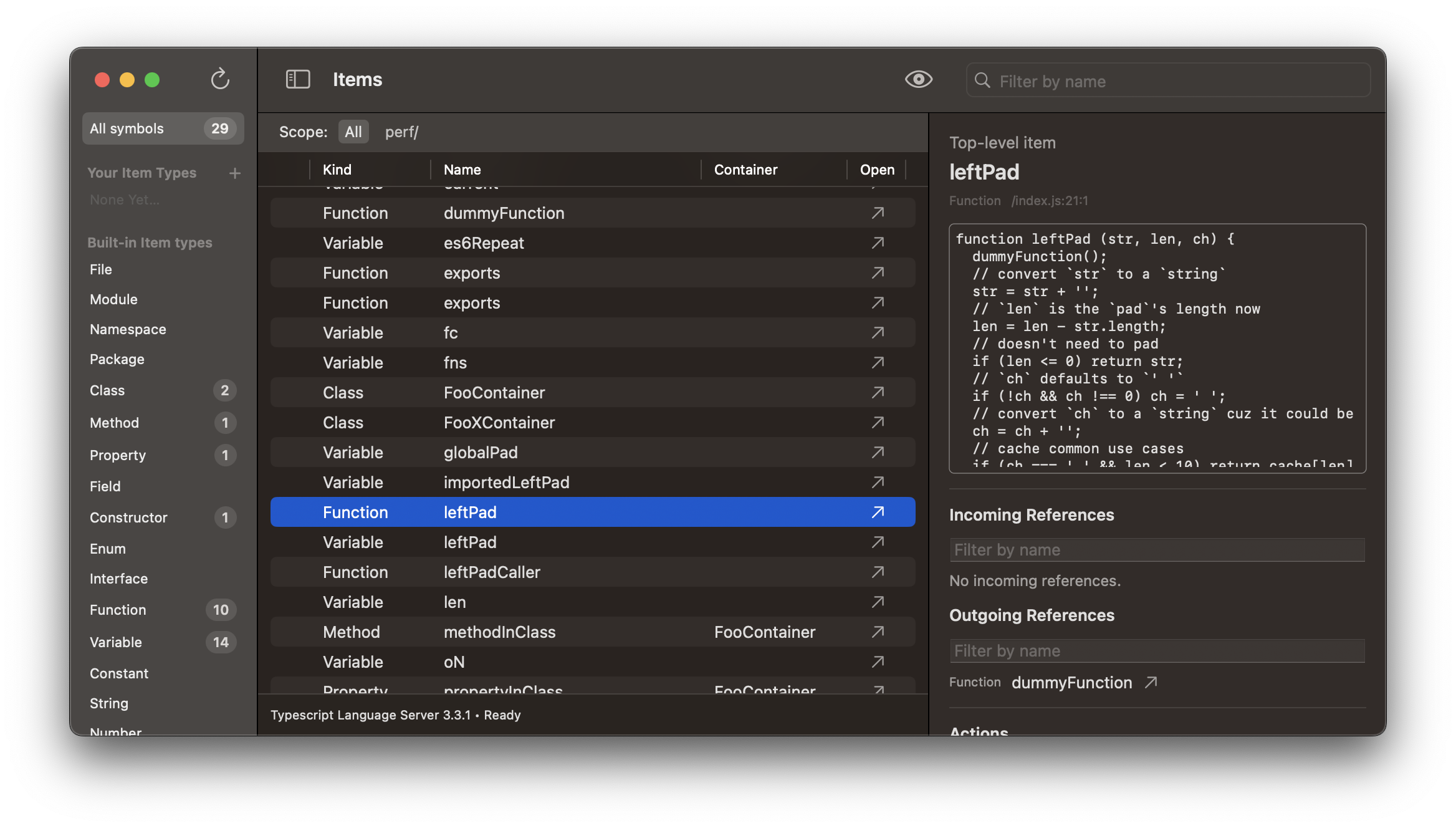 Once you open a project, you’ll see the main view. It’ll start out empty; click the refresh button in the top-left to load all the items defined in your codebase. As it’s running, it’ll show a circular progress indicator that’s based on the number of source code files in your directory (not just at the root level; Tanagram does a deep traversal). If the progress indicator appears stuck with ~100% CPU usage, it’s probably chewing over a large source file — in my testing so far, a 23k line/1.2MB source file took about 33 seconds to process on a Xeon W-3235 (although it’s constrained to a single thread). Reload performance is definitely an area for improvement; for now, you can use project settings (more on that below) to filter out really large files (e.g.
Once you open a project, you’ll see the main view. It’ll start out empty; click the refresh button in the top-left to load all the items defined in your codebase. As it’s running, it’ll show a circular progress indicator that’s based on the number of source code files in your directory (not just at the root level; Tanagram does a deep traversal). If the progress indicator appears stuck with ~100% CPU usage, it’s probably chewing over a large source file — in my testing so far, a 23k line/1.2MB source file took about 33 seconds to process on a Xeon W-3235 (although it’s constrained to a single thread). Reload performance is definitely an area for improvement; for now, you can use project settings (more on that below) to filter out really large files (e.g. vendor/ files or those from node_modules/).
The left sidebar lets you filter codebase items by built-in item types or custom item types (more on that below).
The main list in the middle shows items from your codebase, which you can filter:
- By item type, using the left sidebar;
- By top-level directory, using the scope bar;
- By name, using the search box in the top-right. The Open link will open the file, line, and column at which the symbol is defined in VSCode.
The inspector on the right shows details for the selected item, including:
- Its container (i.e. lexical parent) — a codebase item in which the selected item is nested;
- A preview of the item’s implementation;
- Incoming references — other codebase items that call or refer to the selected item;
- Outgoing references — other codebase items that the selected item calls or refers to.
References Graph
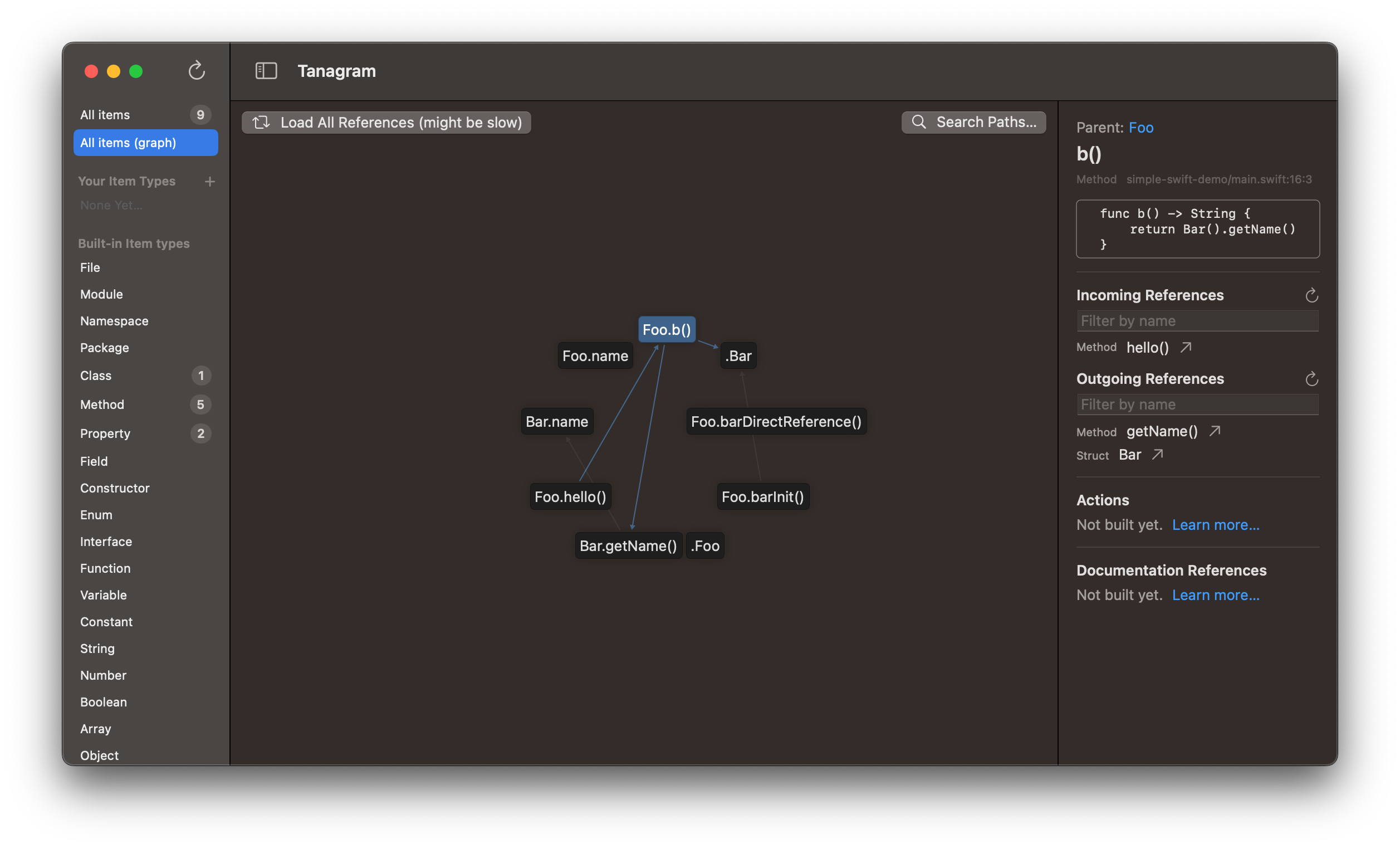
One of Tanagram’s most powerful features is the references graph. This shows all the items within your codebase as nodes on an interactive graph — unlike a static bitmap, you can click on nodes to see details about them, just like if you’d selected them in the main list view.
When you select a node, it’ll load incoming and outgoing references for that node, if they haven’t been loaded already. You can also click the “Load All References” button in the top-left to load all references. For Swift projects, this may take a long time — in my testing using Tanagram’s own codebase, it takes about 12 minutes(!) to load all references for ~10k lines of Swift across ~50 files (it’s bottle-necked on sourcekit itself). I’ll definitely have to make that faster, but in the meantime, try opening a smaller codebase or subdirectory.
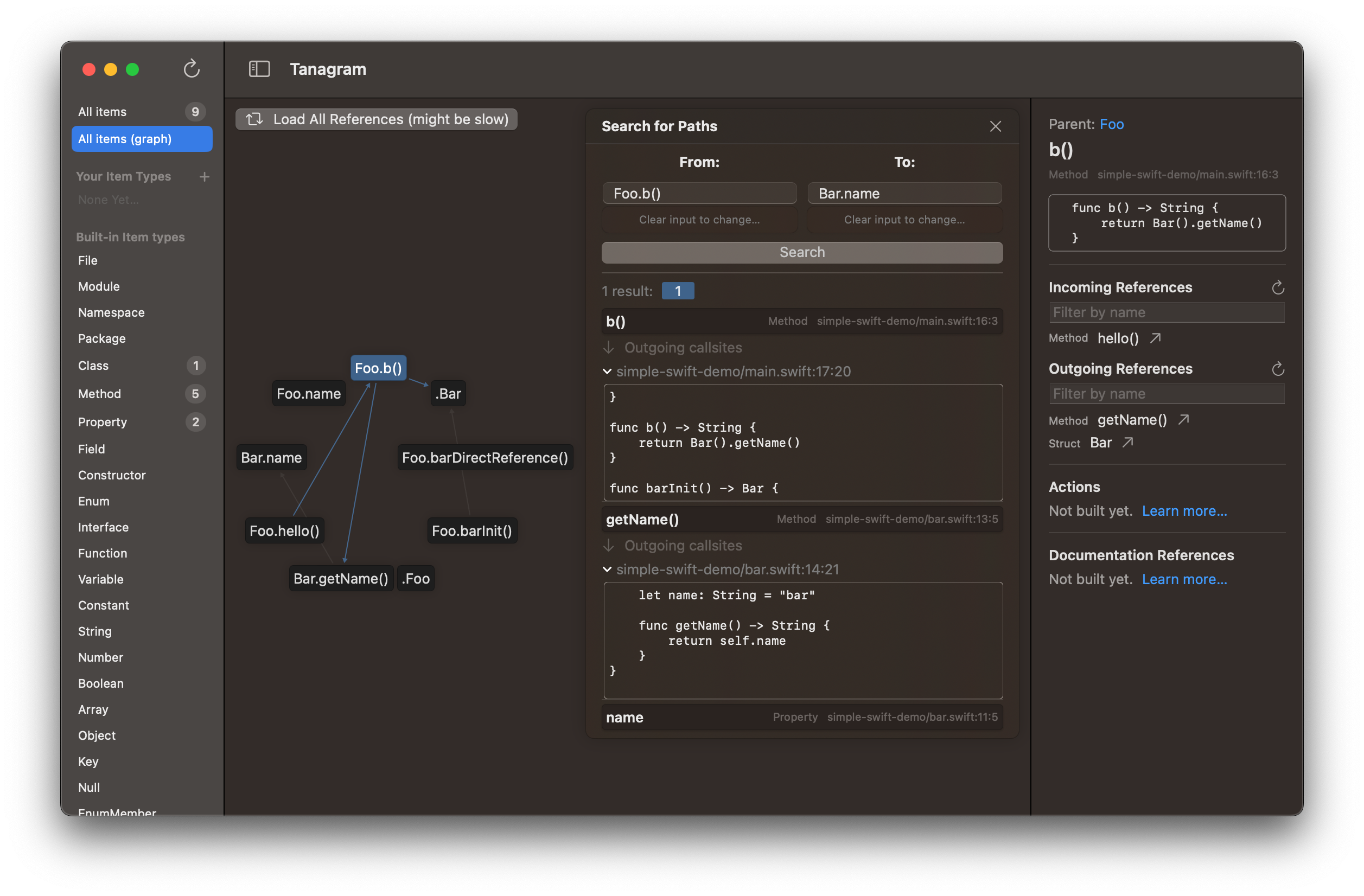
The references graph is powerful because it lets you search for paths between any two items. A path is made up of outgoing references — e.g. there’s a path from A to B if A calls X, which calls Y, which calls Z, which calls B. Reference types aren’t limited to method calls; this example shows a path from the Foo.b() method to the Bar.name instance variable.
Paths will show you a snippet of source code around where each reference was found.
Custom Item Type Definition
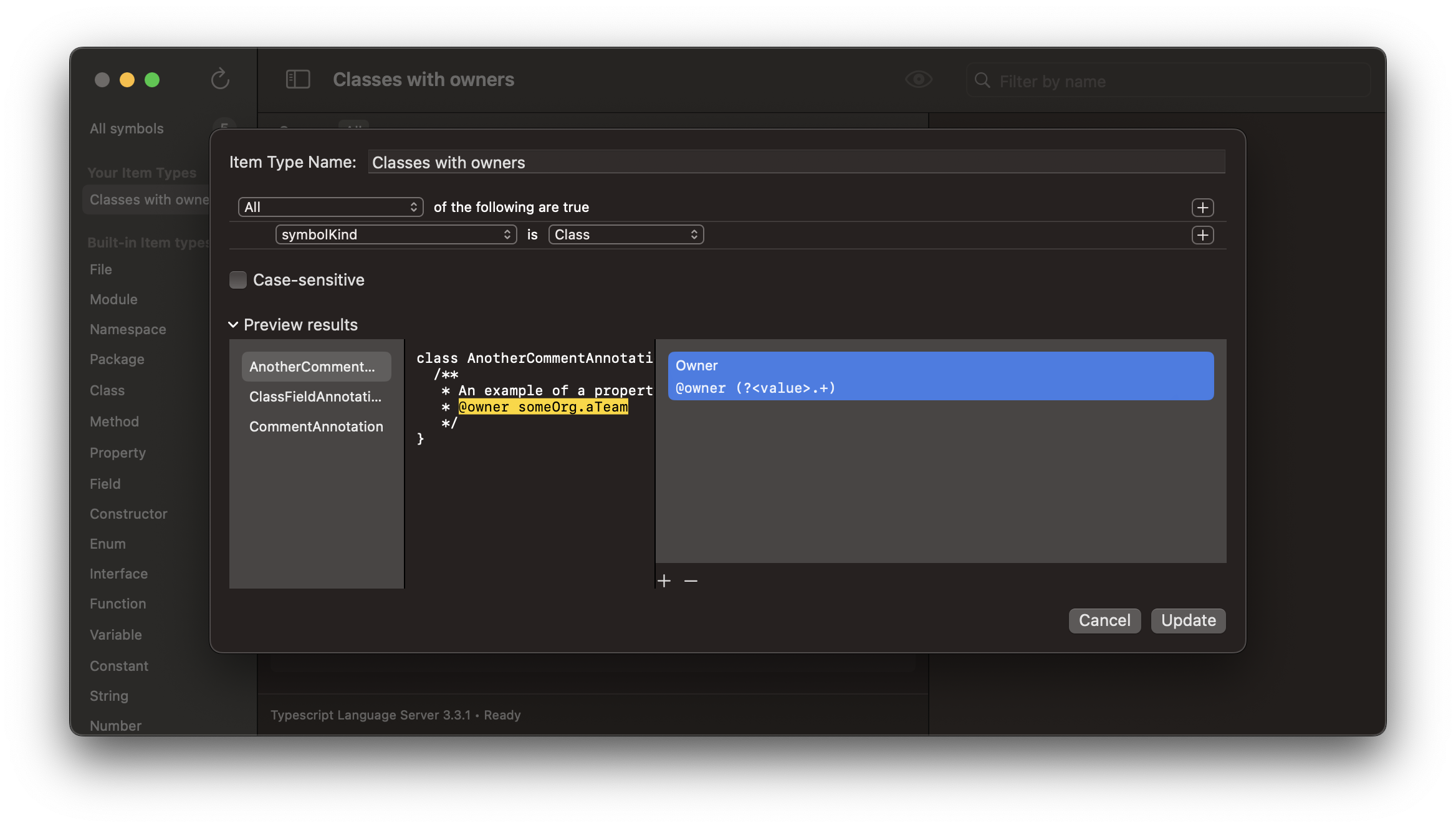
Another powerful feature is the ability to create custom item type definitions. They allow you to identify types of constructs that exist in your codebase by convention. For example:
- You may have API endpoints whose implementations are in an
api/folder and whose filenames end in_method. - You may have a bunch of constants that manually group some IDs that are scattered across the codebase but follow a naming convention — perhaps groups of API methods for your documentation, where the constants are all named
DOCS_SECTION_*; or groups of high/normal/low-priority background jobs, where the constants are all namedJOBS_*_PRIORITY. - You may have cron jobs scattered in folders across the codebase, and you want a unified list of all of them along with the time they’re scheduled to run.
Custom item type definitions will appear as their own entries in the left sidebar.
Once you’ve filtered the items you’re looking for, you can define custom field matchers, which are regex patterns that let you extract important information from the source of each item. Since Tanagram statically operates over your source code, this can include information in comments. Field matchers will highlight matching content in the source code preview, and a capture group named value can be used to extract a custom value for the matcher. For now, matchers only support the first matching result in an item’s source code; any subsequent matches won’t be included in the extracted value.
Extracted field values appear in additional columns in the main content list. This allows you to define a custom data model schema for browsing your codebase. For example, the “Owner” example in the screenshot example above shows up as an “Owner” column here:
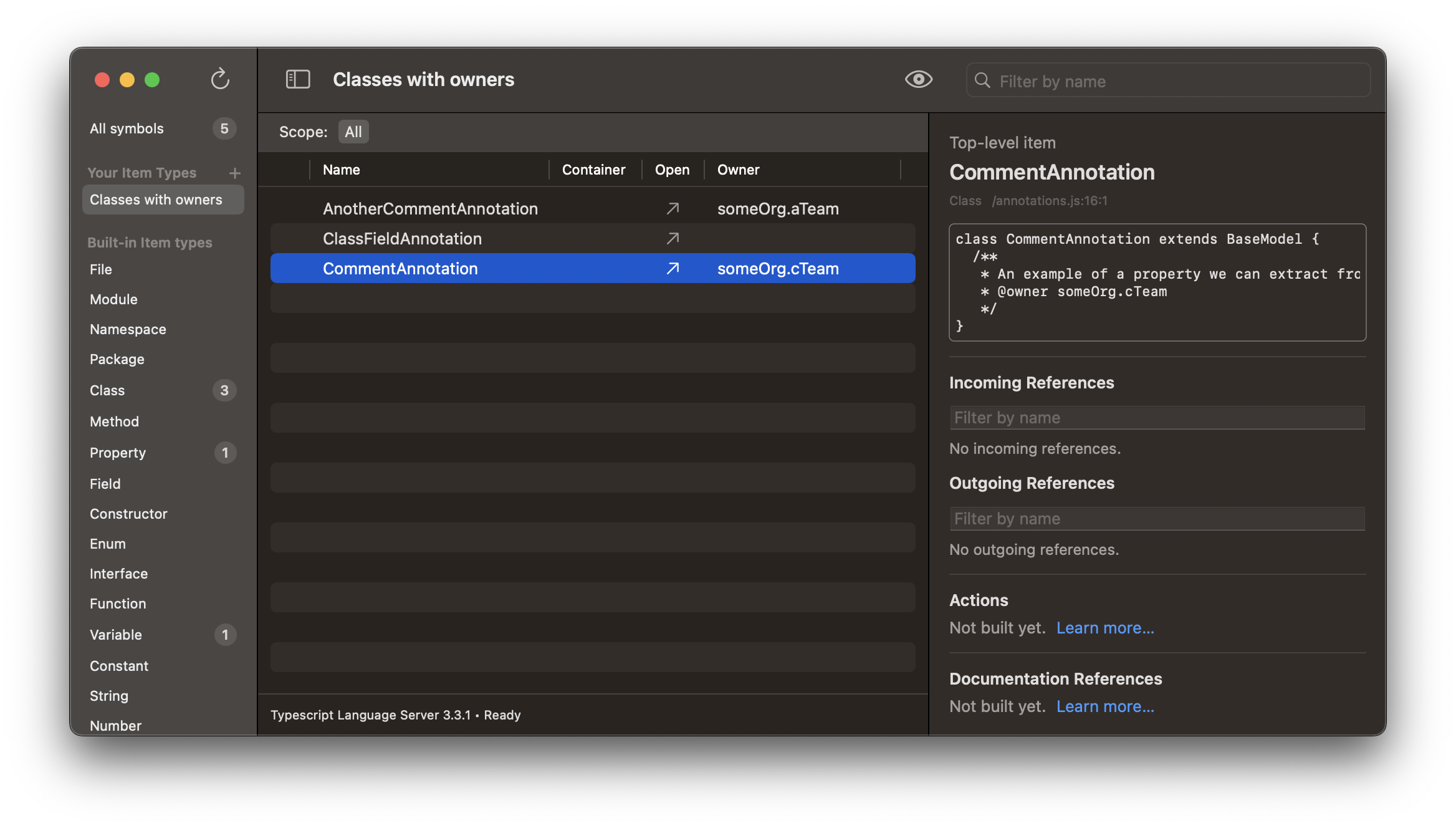
Project Settings
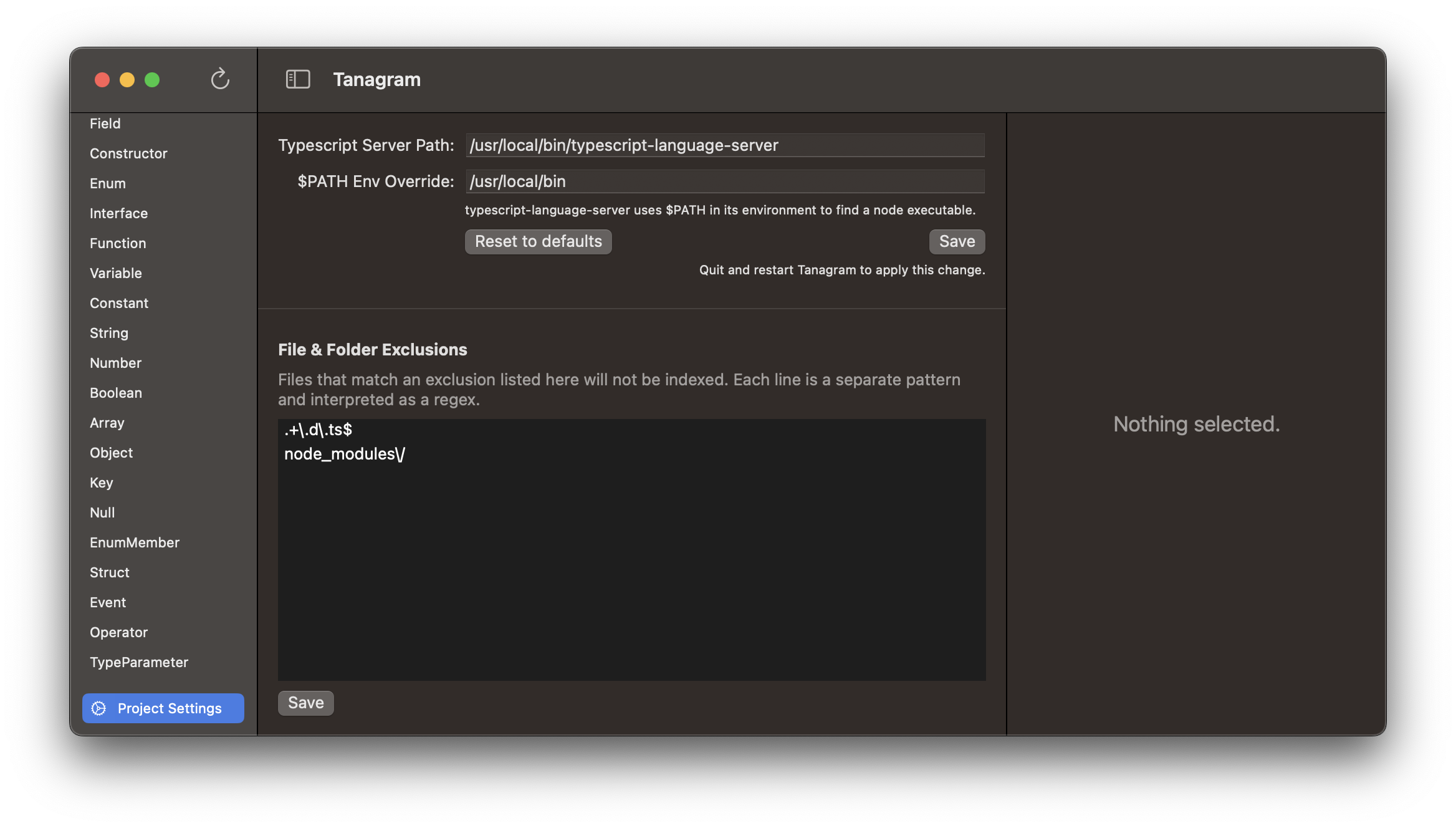
If you open a Typescript/Javascript project, you’ll see a Project Settings entry at the bottom of the left sidebar. Here, you can configure environment settings, as well as file/folder exclusions.
Tanagram uses a language server to parse source code. It doesn’t bundle one, so you’ll have to have one installed. For Typescript/Javascript projects, Tanagram uses typescript-language-server, and by default expects it to be at /usr/local/bin/type-script-language-server. If your binary is somewhere else, you can change the setting here. typescript-language-server also depends on node to be available in its $PATH when it runs. By default, Tanagram runs typescript-language-server with /usr/local/bin as $PATH, implying that you have a node binary at /usr/local/bin/node. If your node binary is in a different directory, you can set that directory here. Click Save to save your changes and restart Tanagram to apply those changes (sorry for the inconvenience).
You can configure files and folders that Tanagram should ignore — specify one regex pattern (not glob pattern) per line. For Typescript/Javascript projects, Tanagram defaults to ignoring .d.ts files and anything in node_modules/.
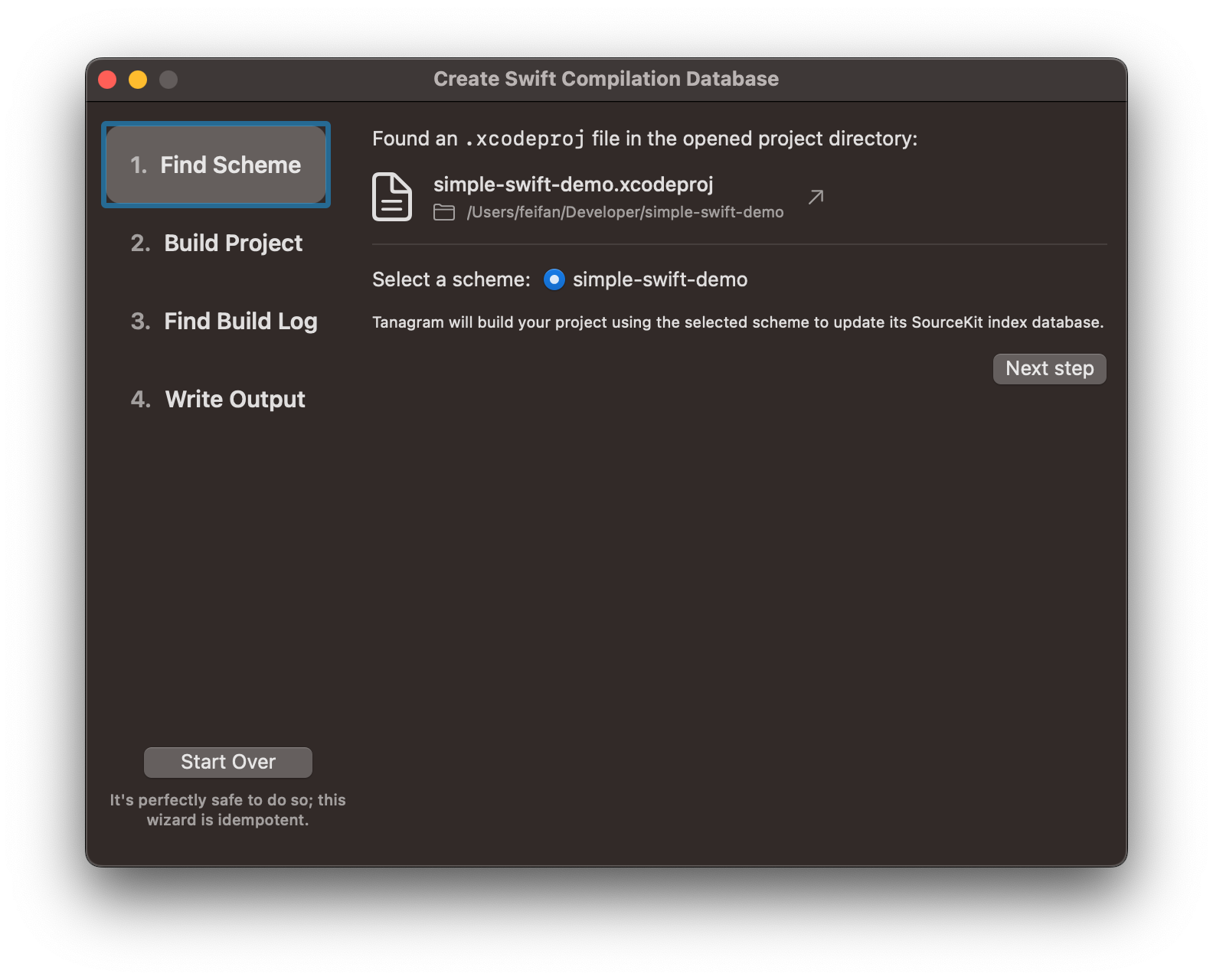
If you open a Swift project, you’ll also see a Project Settings entry at the bottom of the left sidebar. Currently, this just shows an option to open the compilation database wizard:
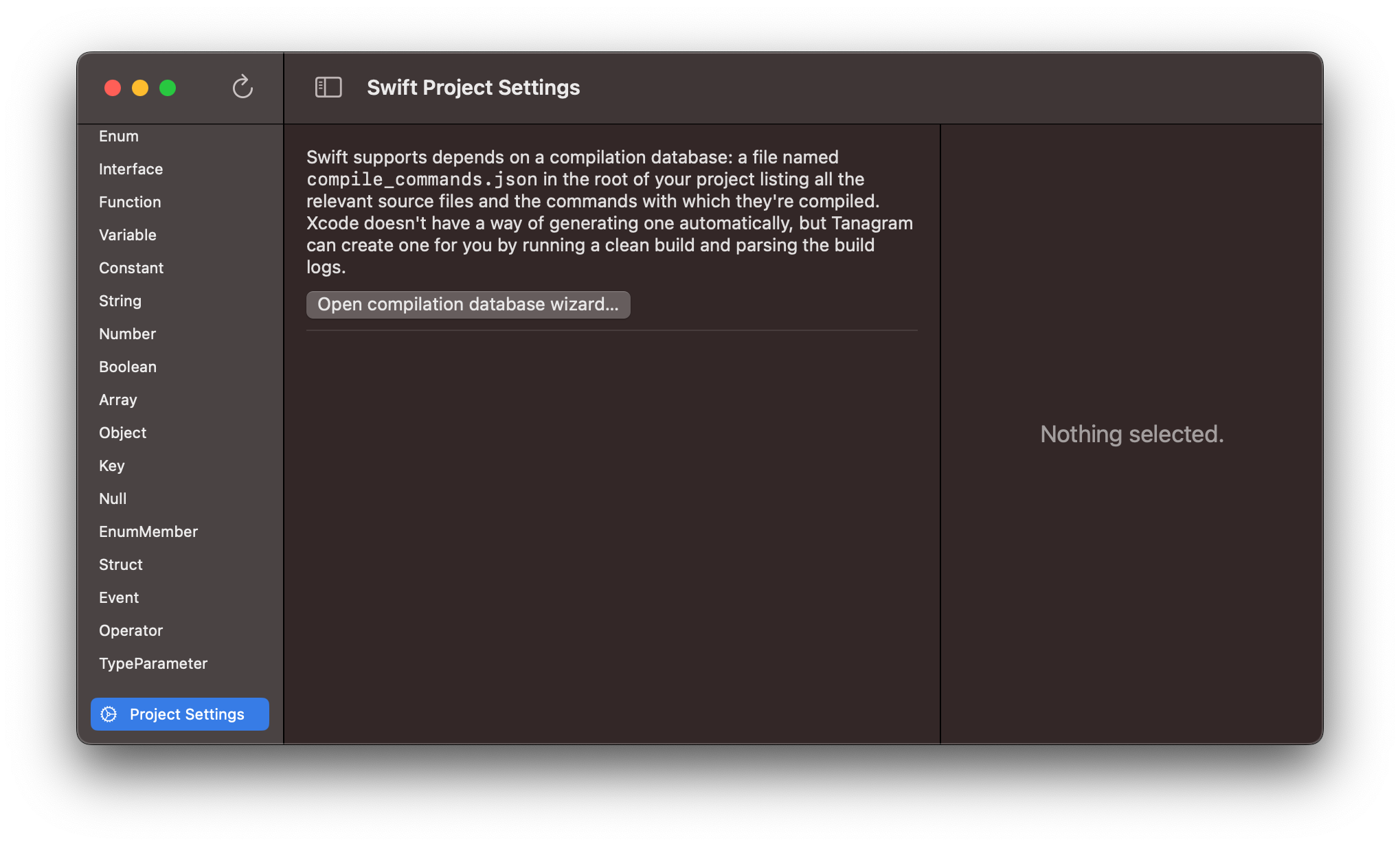
Swift support comes from SourceKit-LSP, which updates its index/understanding of your source code as a side-effect of running an Xcode build (i.e. it doesn’t update live from the file system). SourceKit-LSP finds its index via a compilation database, which is a JSON list of all the files that got compiled in your project as well as the command used to compile it. If a source file is not listed in the compilation database, Tanagram will still run, but you won’t get any results (i.e. incoming or outgoing references) for code items from that file.
In fact, if you open a Swift project without a compilation database, it’ll start by prompting you to create one:
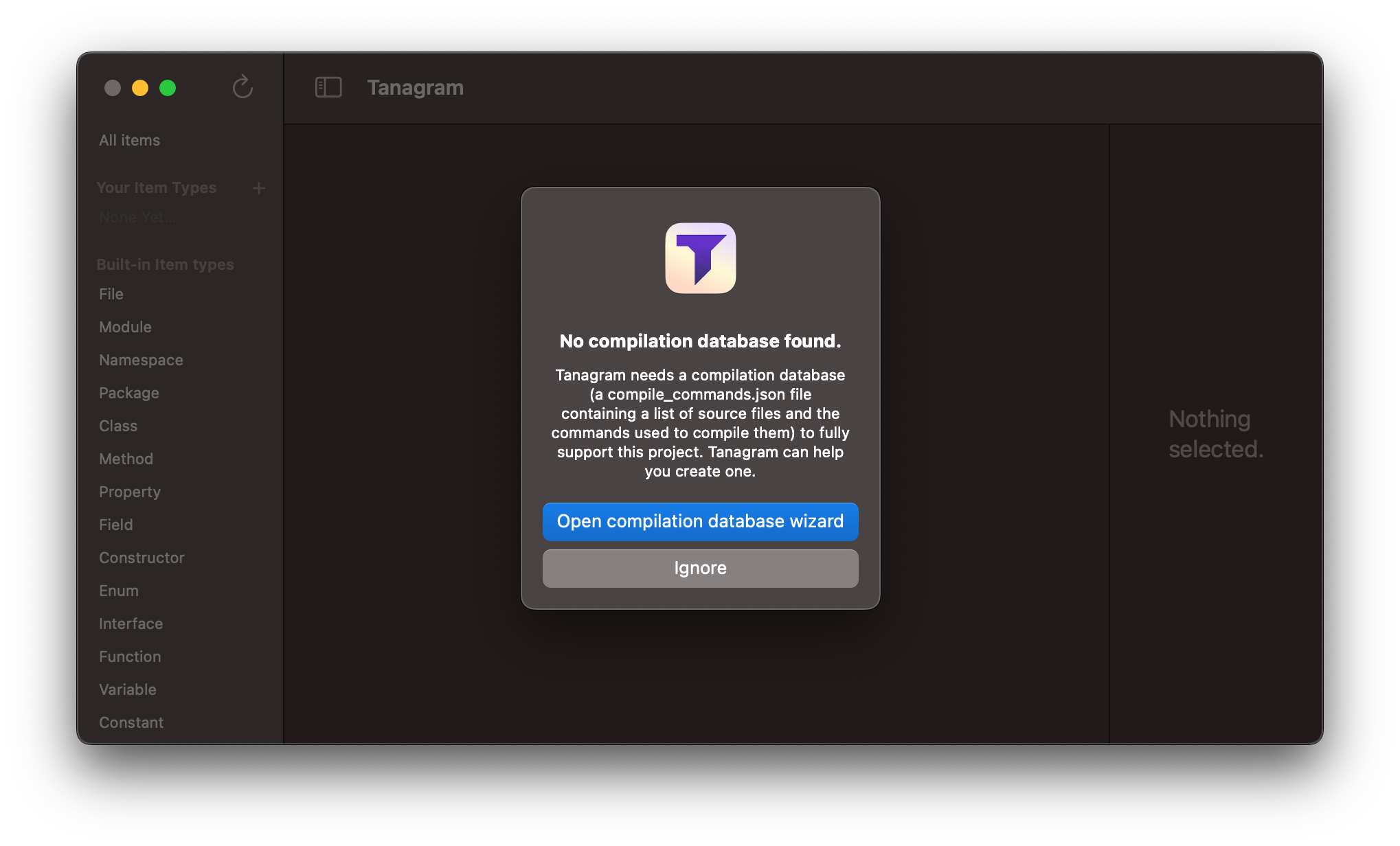
The compilation database wizard will guide you through 4 steps, culminating in a compile_commands.json file written to the root directory of your project. You can gitignore this file.
Live Updates
I’ve spent the last few weeks working on live-updating Tanagram’s data when source files change on disk. Here, I’m creating a new property. When I save the file, the new property automatically shows up in Tanagram. Removing it from the source code also tombstones it in the UI. pic.twitter.com/GNNROU04ws
— Tanagram (@tanagram_) April 1, 2023
Tanagram has some limited support for automatically updating its list of items as you edit the underlying source code:
- If you define new items in an existing source file, or create a new source file within an opened directory, those new items will get added to Tanagram’s database.
- If you remove an existing item from a source file, or delete a file, those items will be tombstoned and faded out in the UI.
- Renaming, either of files or codebase items, is currently not supported — the old names will be tombstoned and the new names will get added anew. This tweet explains why. This also means that if your editor saves changes by writing to a temporary file and then moving that file to the intended path, those changes may not be properly supported.