COMPUTERS HAVE GONE WRONG (AND IT'S ALL SOFTWARE'S FAULT)
Computers Have Gone Wrong (And It’s All Software’s Fault)
You’re reading this on a computer. It is likely one of the most powerful individual computers ever made. You probably have a few more of a similar caliber nearby. What can you do with that power? Can you get it to help you keep track of some kind of information that’s important to your life, and then search through that information in a useful, reliable way? Can you enlist your computer to compute some insights — or just some arithmetic — that you care to know across the information you’ve collected? Can you do it all in the specific way that you would like to do it?
Very many people have computers, and despite the broad range in the way they’re used, there’s a distinct bifurcation in their user base — between those who can fully utilize the computer’s capabilities, and those who can’t (and are left looking for solutions that someone else has built that happens to work for them).
“Learning to code”, i.e. learning to create mobile apps and websites, is an important step in fully utilizing computers, but it’s only one part of it. Computers also need become easier to build for and learn. Computers are tools for creating new tools, and to effectively play this part, it must be easier and faster to create the tool than to do the corresponding work manually. The arrow of progress must point towards making this true for ever more people, and ever more trivial manual work. This has not been the case.
Below, in no particular order, is a list of what I consider problems in the software that underlie the modern computing experience. Some of these problems can be framed in contrast to the computing experience during the early days of UNIX or NeXTSTEP — the computing experience was often more straightforward during that time. That line of thinking doesn’t account for the increased complexity inherent in computing as a result of things we can do now that were impossible then. The problems aren’t listed here to be implicitly dismissed with “we should just think harder and make things the way they used to be”. Instead, I believe it’s valuable to articulate these problems, especially those that are somewhat insidious, as a starting point for thinking holistically about what solutions might look like. This is not an exhaustive list, and I expect to update it over time.
General computing experience
- The predominant modality is “applications” that bundle a data store along with the interface to access that data. This leads to a couple of problems:
- As a user, you’re stuck with the interface that the creators provide you. If you don’t like it, if you want to change or extend it, if you want to access your data in a way that isn’t currently supported, there’s not much you can do besides filing a feature request and hoping it gets implemented.
- It increases the overhead of building an alternative — if you want to build some improvements to an existing application, you first have to build your own datastore and get to feature parity (at least in important workflows) with the existing application before you can get to the differentiating bit. This makes small improvements infeasible.
- Actions are done inside applications, which adds a degree of indirection. This can sometimes be non-trivial. Note-taking apps are perennially pernicious for me: if I have a thought I want to record, should I put it in Notes.app, a text file somewhere in iCloud Drive, Roam, or somewhere else?
- Many (most?) things could benefit from some graphical, interactive UI, but building GUIs is hard (relative to shell scripts that see the entire world as text).
- Notably, new software appears to be predominantly built for the web, but the web platform lacks strong UI primitives. There seems to be a ceiling on the complexity of modular components; why isn’t there a
<list>HTML tag with the features and performance of UITableView that everyone uses? - More abstract interactions could also benefit from stronger primitives provided by the platform
- Notably, new software appears to be predominantly built for the web, but the web platform lacks strong UI primitives. There seems to be a ceiling on the complexity of modular components; why isn’t there a
- History amnesia
- User input, and state more generally, defaults to being discarded. Remembering and being able to restore state is ad-hoc and unreliable. For example:
- Scroll state is almost never preserved, even though you might’ve spent a long time scrolling around to find something.
- In web forms, it’s likely your input will be lost if you refresh the page (or if the page gets refreshed by some force outside your control). If there’s an error submitting your form, your input is often lost as well.
- Clipboard history is lost by default unless you know that apps exist to preserve clipboard history and keep one running.
- The history of actions is implemented differently by each application, and sometimes inconsistently within one application. A lot of actions are not recorded. For example:
- Most modern web browsers have a way to undo closing a tab or window. Most other applications have no such undo when you close a window or document.
- Google Docs ostensibly records a history of document content versions, but comment history is displayed in a completely separate interface. There’s no way (as far as I can tell) to unify the history in a way that shows how the document has evolved in response to comments. Similarly, there’s no way to temporally group comments to show which comments came before others (i.e. to represent “waves” of feedback)
- Undo in Roam is broken in ways I can’t comprehend. It often swaps the order of characters in my input, and sometimes re-orders entire blocks in a way that doesn’t mirror the actions I’m trying to undo.
- User input, and state more generally, defaults to being discarded. Remembering and being able to restore state is ad-hoc and unreliable. For example:
- The cloud is not evenly distributed (the phrase comes from a distillation of this post, although my point here is a bit different from what Johnny is saying)
- The vast majority of computer users don’t know how to directly use “the cloud” — both in the metonymic sense of bringing large-scale/parallel computation to a problem, as well in the prosaic sense of spinning up servers that can automatically scale and be globally accessible.
- Some access is possible but mediated through service providers (e.g. if I want to archive some data and make it linkable, it’s much more straightforward to do that with Dropbox or iCloud Drive than to use S3 directly). But this introduces all the problems with applications.
Programming
- There’s a lot of overhead in creating a new project
- Sometimes it’s overhead from your programming environment/IDE. Sometimes this is straightforward (e.g. follow the steps to create a new project in your IDE). Other times it’s not (e.g. creating a browser extension).
- Using service providers (e.g. Stripe, Twilio, etc.) is a manual process of creating accounts and copy-and-pasting API keys to a variety of locations.
- The way you’d describe a system often doesn’t show up in code anywhere
- Imagine the system diagram you’d draw to explain things to a new teammate. Would it be impossible, or merely difficult, to programmatically draw such a diagram and keep it updated with your codebase?
- Async event-driven systems and user flows are particularly tricky. If you have an async pubsub pipeline, is the sequence of events and consumers listed sequentially anywhere in the codebase for easy understanding? If you have a user-facing flow that existed as an ordered sequence of mocks at the design stage, does that same sequence of pages or components exist in one place in your codebase?
- When a program runs into a bug, losing state is the default behavior, which makes it difficult to debug unless you can make the bug happen again.
- In modern OSs, native apps crash and lose all their memory state.
- In browsers, being able to inspect network requests is great, except that any requests made before the Inspector is opened gets lost.
- Scheduling something to happen in the future is hard/unreliable.
- If you’re trying to do this on your local computer, you’ll have to account for your computer being asleep.
- If you’re trying to do this on a remote server, there’s a lot of overhead in spinning up a server, deploying your command to it, and adding it to the cron config.
Terminal/Shell scripts
- Shell programs take inconsistent, ad-hoc, sometimes obscure inputs.
- Sometimes also inscrutable.
- This includes ways of getting to documentation — some programs take an
-hand/or--helpflag; others provide amanpage; others do both (with different content); or neither.
- Relatedly, the “everything is text” philosophy means all inputs and outputs need to be coerced into text.
- Different scripts do this differently, and to various levels of terseness or user-friendliness.
- Some inputs/outputs are just awkward to convert into text (see LaTeX).
- Pipes are a great concept but aren’t robust enough in practice.
- Many programs benefit from having verbose/formatted output, but also need a non-verbose mode for effective use with pipes. Non-verbose output is implemented inconsistently.
- Handling errors within a pipe sequence is awkward.
GUIs
- GUIs often aren’t composable.
- For example, on macOS you can see the definition of a word in a popup modal.
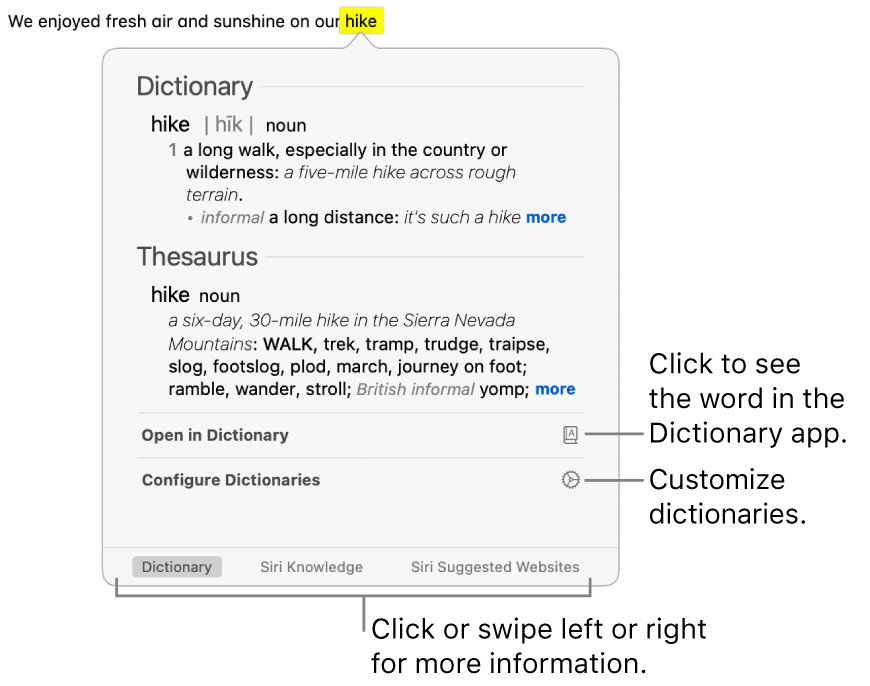 However, you can’t lookup any of the words in that modal using the same gesture (or any other way that I’ve found).
However, you can’t lookup any of the words in that modal using the same gesture (or any other way that I’ve found). - The semantic structure of data on screen is often inaccessible. Try copy-and-pasting from a chat client, and you’d be lucky to get something readable without additional processing. There’s no way to get an array of message-content strings or workable data structures. Or — if you have an HTML table, and you want to sort or filter the data in it, what can you do? There’s no clear way to preserve the tabular structure of the data and turn it into a data structure you can easily manipulate.
- For example, on macOS you can see the definition of a word in a popup modal.
- The lack of strong UI primitives on the web make it easy to break native interactions — there’s no pit of success.
- For example, it’s very easy to build a form (or at least some UI that looks like a form) that doesn’t submit when the Return key is pressed.